Array based semi-mutable sets – consolidation
October 25, 2015 Leave a comment
The approach described so far minimized the write activity by creating arrays of events that overlap in time. Storing events in arrays results in extremely fast reads, while the only-add-don’t-modify existing data limits the cost of writes. We even saw that in some cases it might not even be necessary to sort the events by time.
Although it was easy to find all events within a time range using simple binary searches, the fact that the events are not fully ordered renders some calculations impossible. For example, any calculation that relies on the time interval between events is pretty much impossible unless all the events are ordered. Similarly aggregation, compression and decimation become much easier or simply feasible when the events are ordered.
The other problem I can see arising is the multiplication of small arrays, there is a point where too many small arrays renders the approach counter productive. The solution to this is to consolidate several arrays into larger ones. This can be done at any time, even when new events are added. Alternatively it can be limited to older events, for example, when one knows that no event older than some time limit will be added to the system.
The following diagrams illustrates the process:
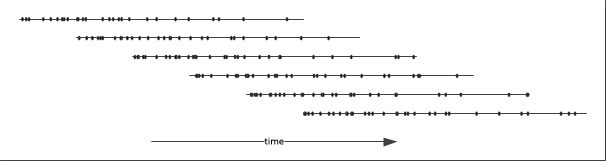
Each line represents an array of events, each dot represents an event. In this example only five arrays overlap. The state of the system after consolidation is then:
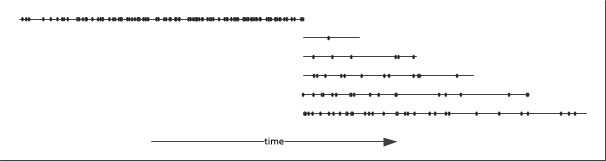
where the consolidated array contains all the events within a predetermined time range. Whether one will want to sort the events within the arrays is again a question of “it depends”. In particular it will depend on the size of the array and the expected queries.
My code consolidates all events older than 30 minutes over one minute periods, so that the new event batches contain on average 180’000 events. The consolidation process consists of copying the events to a new array and replacing the truncated batch instances with new one. To optimize this process and avoiding copying the events that are not consolidated unnecessarily I added a new field to the batch class that specifies the first valid event in the event array. This way the (immutable) array of events is reused by the new batch instance.
public struct TradingEvent : IComparable {
public long Id;
public long Time; // unix milliseconds
public short Price;
public short Volume;
public short Stock;
public short BuyerId;
public short SellerId;
public short TraderId;
public long FirstEvent; // the index of the first event after partial consolidation
public int CompareTo(object other) {
return Time.CompareTo(((long)other));
}
}
If the small arrays are not sorted, each has to be enumerated to extract the events to be moved to the consolidated array while the remaining ones have to be moved to another array. Potentially one could avoid the second copy operation by adding a filter field to the batch class.
Since I am consolidating over a fixed time period rather than for a fixed array size, the size of the consolidated arrays varies around an average of 5.5 MB. The CLR stores these relatively large arrays in the Large Object Heap. By default the garbage collector does not compact this heap due to the potentially high cost. The downside of this approach is memory fragmentation. There are two ways to avoid this problem, firstly one can ask the garbage collector to compact the Large Object Heap (see here) or use fixed sized arrays.
The consolidation process takes place once every minute, the cost of this operation is dominated by the sorting of the consolidated array. Currently I am using the Array.Sort method. Since the array is already partially ordered a different sort algorithm might improve performance unless it is more efficient to directly merge the arrays rather than copying them and then sort.
On my laptop the sorting takes on average 27 ms, executed every minute this represents a minuscule proportion of time.
Now there are many other ways the events can be stored, the events could be grouped by some property such as the ticket, so that for any time interval there would be as many arrays as tickets. This is just one form of indexing. Again any indexing is possible, it all depends on the use case. This can be taken even further if we have another continuous variable: events can be grouped by range in two or more dimensions. Thus providing double indexing of events.
All this is made easy by the use of transactions as all writes are performed atomically. So at any time it is extremely easy to modify or extend the way the data is stored while maintaining consistency and allowing many readers to run unobstructed.
Note that if time ordering of events is not required within a set, the events can be sorted on any other property. This becomes be particularly interesting if that other property is another continuous property.
