October 5, 2015
by Gabriel Horvath
Now a typical example where many items can be added within single transaction is when a database collects time stamped events also called time series. One can easily imagine a system where many thousands of events are added to a database every second. Obviously there is no point in creating a single transaction per event and in general one can batch them together. The delay between consecutive batches will then depend on the acceptable delay for events to be made available to the database readers. One can imagine batching periods ranging from the order of milliseconds to many seconds or more. Overall the important parameters of such a system are:
- event production rate
- batching period
- events retention period
Together these parameters will determine the liveliness and memory usage of the database. As an example consider NASDAQ trades. About 20 billion shares are traded every day on the NASDAQ, assuming an average of 300 shares per trade (approximate NYSE numbers) and a trading day of 7 hours there are, on average, about 3000 transactions per second. Assuming a retention period of 5 days, we are talking about keeping about 350 million trading transactions in memory. With a batching period of 1 second, we will be creating about 117000 arrays, each containing on average 3000 events. While events are being added to the database, transactions beyond the retention date will be removed by the system. To avoid contention, I will be doing this garbage collection in the same transaction as the one that writes the new events. Essentially I will have a system with a single threaded writer and multi threaded reader.
Implementation
The trading transactions will be represented using the following data structure:
public struct TradingEvent : IComparable {
public long Id;
public long Time; // unix milliseconds
public short Price;
public short Volume;
public short Stock;
public short BuyerId;
public short SellerId;
public short TraderId;
public int CompareTo(object other) {
return Time.CompareTo(((long)other));
}
}
which takes up 32 bytes. The following data structure holds the array of trades ordered by time:
public struct TradeBatch : IComparable {
public Guid Id;
public long First;
public long Last;
public TradingEvent[] Trades;
public int CompareTo(object other) {
var that = (TradeBatch) other;
var result = First.CompareTo(that.First);
if (result == 0) result = Id.CompareTo(that.Id);
return result;
}
}
which are then stored in the following semi-mutable set:
smxSet<TradeBatch> allTradeBatches;
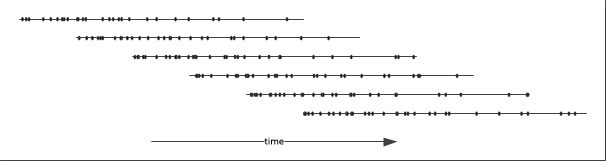
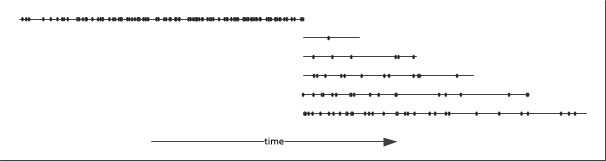
The code first populates 5 days worth of events (about 378 million events, i.e. 11 GB) and then generates 3000 events every second. 500 events are generated with time stamps within the batching period of one second, another 500 events within 2 seconds, then another 500 within 5 seconds, 500 within 10 seconds, 500 within 30 seconds and the last 500 are generated within 60 seconds. This models the case where events are received after some delay. Hence on average about 60 arrays overlap each other in time, or in other words, for any given time, events can be found on average in 60 arrays.
Since the events within an array are sorted, enumerating all events within a time range is just a matter of filtering the batches that overlap with the desired range and then binary chopping the array to get the required indices that match the time interval:
foreach (var batch in allTradeBatches) {
var firstIndex = 0;
var lastIndex = batch.Trades.Length;
if (start >= batch.First && start <= batch.Last) {
firstIndex = Array.BinarySearch(batch.Trades, start);
if (firstIndex < 0) firstIndex = -(firstIndex + 1); }
if (end >= batch.First && end<= batch.Last) {
lastIndex = Array.BinarySearch(batch.Trades, end);
if (lastIndex < 0) lastIndex = -(lastIndex + 1);
}
for (int i = firstIndex; i < lastIndex; i++) {
totalVolume += batch.Trades[i].Volume;
}
}
On average, the binary search should only have to be carried twice on sixty arrays. Once the indices have been determined, all accesses to memory are sequential, i.e. rates of 10 GB/s can be expected, which should translate to 320 Mev/s. Assuming a maximum bandwidth of 50 GB/s when multithreaded, we could expect to read events at the rate of 1.6 Gev/s.
Obviously the binary search adds an overhead. The standard array implementation takes about 4 μs per array fo 3000 events on my laptop. A basic custom implementation, one which doesn’t have to go through the ICompare interface and the unboxing of the long takes 1.4 μs. Assuming 120 binary searches, the current implementation presents an overhead of up to 0.5 ms or, with a custom implementation, 170 μs. To put things in context, this corresponds to the time it takes to sequentially access respectively 160 Kev or 54 Kev.
Interestingly, the binary search time of 4 μs corresponds to reading 1280 events, double that if you have to perform two binary searches and we could have already retrieved 2560 event! Reading the whole array takes almost the same time as performing the binary search! However, this is not the case if one uses the custom implementation, but is still a remarkable fact that highlights the incredible speed of sequential reads. Actually the code to be executed would have to be something like:
for (int i = 0; i < batch.Trades.Length; i++) {
if (batch.Trades[i].Time > start && batch.Trades[i].Time < end) {
totalVolume += batch.Trades[i].Volume;
}
}
So let’s see how this compares to the same loop but without the conditions on the time. On an E5 2666 Xeon machine, it took 36 ms with the conditions versus 29 ms without them to enumerate 3000*3600 events. In other words 300 Mev/s versus 372 Mev/s. So a slowdown of about 20%.
The main advantage this last version is that the arrays do not have to be sorted! Whether this is really an advantage will depend on the actual use case, and in general more time is spent reading than writing, so it is often good practice to do more work only once.
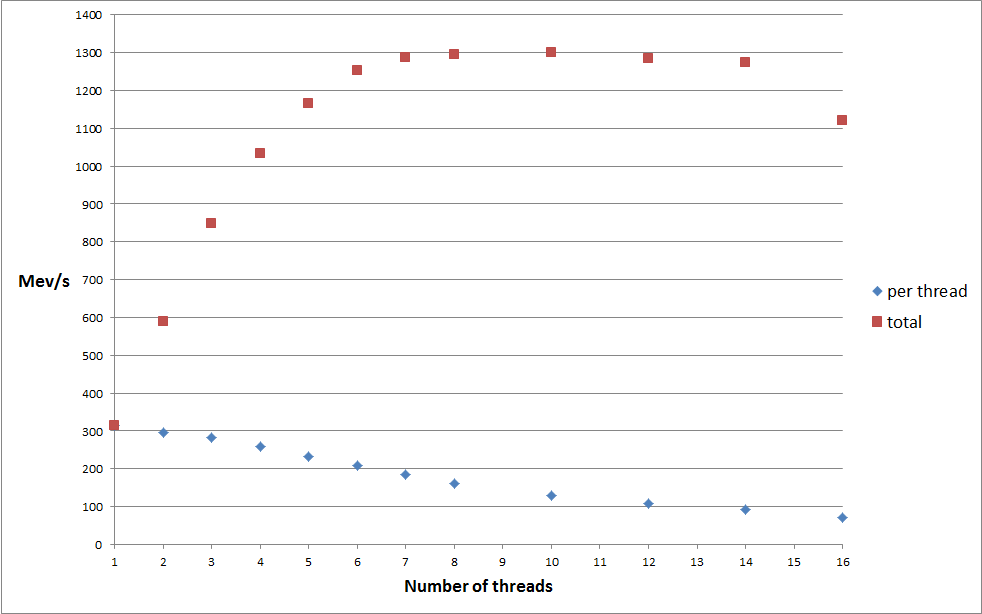
I have executed some more complete tests (still focused on enumerating large numbers of events rather than just a few, so the impact of the binary searches should be negligible). The code is executed in up to 8 threads, each threads enumerates a disjoint set of events, for example, in the case of two threads, the first one enumerates the first half of all events while the second thread enumerates the second half. This way all the data from the event batches is read from main memory rather than from the cache. The events set was populated with 5*7*3600 batches of 3000 events.

Single threaded performance stands at 315 Mev/s (almost 10 GB/s), maximum total bandwidth reaches about 1.3 Gev/s. These results include garbage collection of versions, generation of 3000 events every second, removal of old batches, but no persistence to disk.
Using this approach, the database is populated with 126’000 arrays, which is a lot, also on average 60 arrays overlap in time. Although this approach is most efficient at enumerating all the events within a given time range, it is important to note that overall the events are only partially ordered.
In the next post I shall illustrate how these small arrays can be consolidated into fully ordered larger non-overlapping ones.