I have often wondered how the current many-core CPUs can retrieve enough data from memory to feed all its cores. So I decided to carry out a few simple experiments.
I looked at three different scenarios, sequential memory access, dependent chain memory access and random memory access. The second being the case where the result of a read determines the address of the subsequent read (load-to-use).
In the first case, we expect to reach very high memory bandwidth, potentially hitting the maximum specified in the CPU spec with relatively few threads. In the case of chained memory access the bandwidth will reflect the memory’s full (huge) latency. In the third case the bandwidth should be higher but probably not by much. In all cases I am mainly interested in the scalability aspects, i.e. how does the single thread/core bandwidth scale as more threads/cores hit the memory bus.
Note that the code was put together fairly quickly, far more care should be taken to get accurate results, however this should be good enough to understand the scalability aspects I am interested in.
As the goal is to measure main memory access as opposed to cache access, to minimize the impact of the limited TLB buffer, each thread accesses these same 1GB array of 64 bit longs. The code is available on Github. For the sequential case the core loop is simply:
for (int i = 0; i < max; i++) total += array[i];
The next benchmark is where the addresses of a memory access depends on the value of the previous read:
for (int i = 0; i < max/8; i++) index = array[index];
where the array has been initialized so that the index performs a random walk through the whole array. This models the case where one walks down a dependency path, e.g.
var x = a.b.c.d.e.f;
The code for the random access performance test is:
for (int i = 0; i < max/8; i++) total += array[(i * 11587L) & (max-1)];
where we take large, non-periodic, steps to avoid prefetch and cache effects. Note that since the reads are much slower we perform 8 times fewer memory accesses.
In all of these benchmarks ten runs of one hundred such loops are executed and the best, lowest, time is taken.
I executed this code on three different machines with the following specs:
- 4 cores – i7 2600K 3.4- 3.5 GHz with 16GB DDR3
- 6 cores – Xeon E5 1650 v3 – 3.4 – 3.5 GHz with 16GB of four channels DDR4
- 8 cores – Xeon E5 2666 v3 – 2.9 – 3.2 GHz with 30GB of four channels DDR4
The Xeon E5 2666 v3 is a custom Intel CPU for AWS, you can find more details in The Register.
All the results can be found on Github next to the actual code. Here are the results for sequential access which represents the bandwidth in GB/s as a function of the number of concurrent threads:

First thing to mention is that there is no massive difference between the memory bandwidth of the various systems in the single threaded case. Beyond that the memory bandwidth scales similarly on all CPUs. Where the difference is however significant is how far each system scales. The oldest CPU stops at 20 GB/s (21 GB/s in the spec), while the Xeon 1650 supports double that much (spec says 68 GB/s) and the socket Xeon 2666 with 8 cores reaches 50 GB/s with 8 threads (spec says 68 GB/s). Note that the old CPU uses DDR3 with two channels while the two Haswell CPUs use DDR4 with 4 channels, so no big surprise there.
Althoug not linear, the scalability of each of these is pretty good. The slowest and oldest system scales only up to twice its single threaded performance. The 1650 scales up nearly five times its single threaded performance, while the 2666 goes up to about six or seven times the single threaded performance (albeit starting lower). Note that neither of the Haswell CPUs reaches anywhere close to their spec-ed memory bandwidth of 68 GB/s on the tested systems.
In terms of memory access time, in the single threaded case, the memory bandwidth for the 1650 is equivalent to 0.83 ns access time per long! This number is most impressive, and is down to the quality of the CPUs prefetch unit (actually the streamer) which detects the sequential read pattern and accordingly prefetches aggressively (up to 20 cache lines ahead). You can read all the details (well the ones they made public) about the prefetch unit in Intel’s manual.
Let’s move on onto the chained reads:

where the difference with sequential reads is striking, roughly speaking chained reads are one hundred times slower than the sequential case. This corresponds to a latency of about 90 ns, which is pretty much what one can expect from DRAM nowadays. Note that the bandwidth increases almost linearly with the number of threads and shows no sign of saturating.
Here are the results for random reads. Single threaded bandwidth start a bit below 0.4 GB/s which corresponds to a latency of about 18 ns. Note that in this case the bandwidth increases fairly linearly with the number of threads to saturate at around 2.4-2.6 GB/s.

The difference with the chained reads, a factor of four or five, is due to the fact that since the reads are independent, the CPU can dispatch several of them to the memory controller pretty much concurrently. The memory controller can then take full advantage of the channel and bank-level parallelism as well as memory pipelining to perform concurrent memory reads.
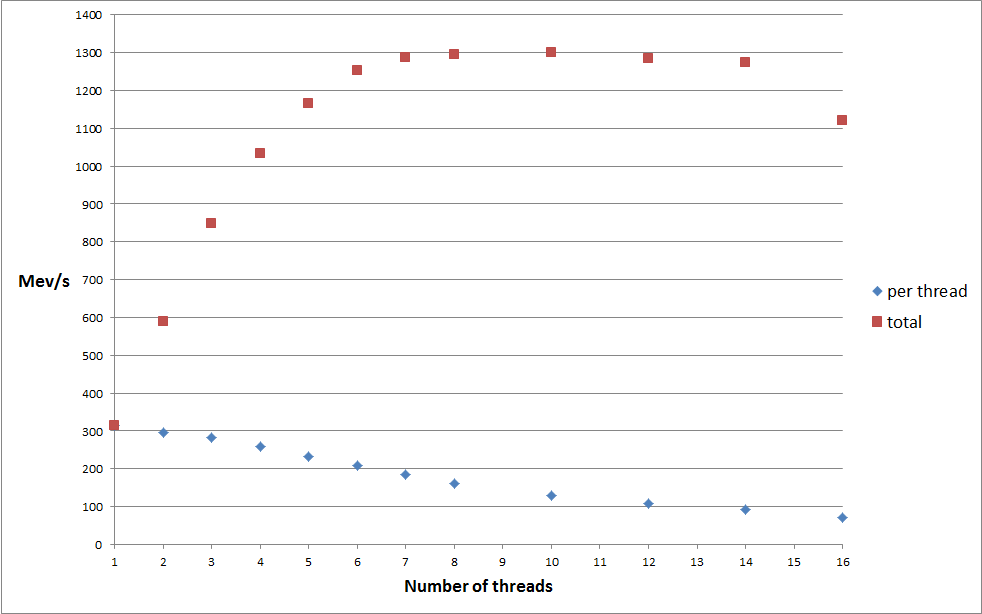
Since this last result seems to indicate that the memory controller is able to dispatch maybe up to five (independent) memory requests concurrently, we could try to take advantage of this by executing multiple chained reads within a given thread:
for (int i = 0; i < max/8; i++) {
index0 = array[index0];
index1 = array[index1];
}
I have implemented this code with up to eight concurrent indices. Since all of these dependent chains access the same array, I made sure that all indices are sufficiently distant from each to exclude any caching effect. The code was executed on up to 8 threads on the 8 cores machine. The abscissa (x-coordinate) is the product of the number of threads and the concurrency level:

In the single threaded case, the maximum bandwidth is 255 MB/s which is very close to the single threaded random reads result of 283 MB/s. When running multithreaded, the maximum bandwidth reaches 1.94 GB/s, again close to the multithreaded random reads of 2.04 GB/s. So, in principle, and possibly at almost not cost at all, one can gain a factor of four in memory bandwidth by executing multiple chained reads within a single loop.
So the bottom line is:
- sequential access is the king, by a factor of twenty to one hundred
- chained reads can be made to run four times faster
In the case of chained reads, the huge 90 ns delay between consecutive memory reads should permit the execution of a large number of instructions, potentially hundreds of them, allowing quite a lot of processing of the retrieved data. This is also the case, albeit on a smaller scale, for random reads.
Many thanks to Asier for suggestions, comments, discussions and comparisons between C++ and C# performance!
[10 April 2016] This graphs in this post have been replaced with the latest version of the benchmark that minimize TLB impact. The text has been edited accordingly.




{kind=link}