Model comparison
December 3, 2014 Leave a comment
A long time overdue post…
One of my preferred slides when presenting my transactional model compares different locking models. I start with the most restrictive model, a single global lock:

where I consider four threads named A,B,C,D. Writes are amber coloured, reads are in blue. Dashed sections represent blocked threads waiting to either write or read. Since there is a single global lock, the execution is serialized, there is no concurrent execution and there is always one active thread and three blocked ones. Long running “transactions” have a direct impact on the system’s throughput.
Things improve “dramatically” when we swap our single global lock for a reader-writer lock:

Hey it’s concurrent now! Well as long as we read we have concurrency, but as soon as we want to write all the reader threads are blocked. But still a huge improvement over having a single global lock. Also the writer thread has to wait for all reader threads to terminate before it can acquire the writer lock. The reader threads cannot be allowed to last too long if we want to have to give the writer thread a chance to update the system. So there are still some serious constraints. On the positive side there is one important property: since only one writer is allowed, with no concurrent reader, there is no need for any transactional mechanism, all writes performed can only be read after the writer lock has been released. So no partial writes can be observed by any reader. Long running “transactions” still have a direct impact on the system’s throughput: long running read transaction prevents writes and vice-versa.
Next comes the versioned system:
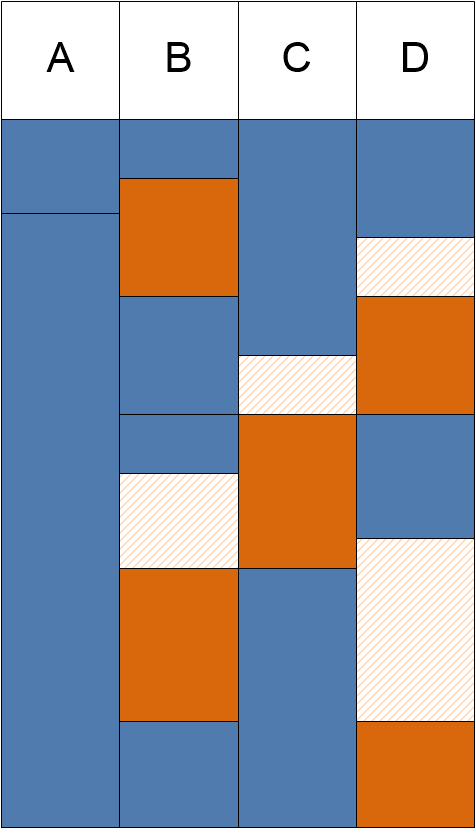
which uses a single, global writer lock. As before we can have any number of concurrent readers; the novelty is that since existing versions are strictly immutable, the reader threads can be executed concurrently with a writer thread. So in practice a reader thread can last as long as needed (at the cost of having to keep some versions in memory). We still have a single writer lock, so a thread that wants to perform writes has to wait for the lock to become available. So we are still single threaded in terms of writes. As a consequence there is still no need for any transactional mechanism as partial writes cannot be observed. Long running read-only transactions are possible, we can also have long running write transactions, but at the cost of blocking other would-be writers. The cost of moving to this higher level of concurrency is an increase in memory usage as all accessible versions must be preserved. Note that write transactions cannot fail when we are dealing with essentially single threaded writer systems. Additionally the thread can directly modify the versioned variables, no need to delay the writes to the commit phase. This model can also be fully single threaded in which case we get:

The last model is the one I have described in this blog:

Here we are adding support for long-running concurrent write transactions. In terms of locking we have the single global version lock which is very short (increment a number and copy it) and the longer per transactional box/variable lock that must be taken for the duration of the validation and update phase. In the above diagram we have thread A waiting on thread D to acquire a box lock and later we have thread C waiting on thread D. We have seen before that this can be sometimes mitigated by partitioning the data.
This last model comes at a cost: registration of reads and writes during the execution of the body of the transaction, validation stage and commit stage. Concurrent writer transactions also introduce the risk of conflicts, but we have seen that leveraging the semantics of data structures can greatly reduce this risk.
Any system with a decent level of concurrency will, most likely have to use at least versioned variables. We must remember that server processors can have up to 18 Intel cores (expensive, $4115 ) or 16 AMD cores (cheaper, $719) You can use dual socket, 8 cores per processor, systems in the cloud, that’s 32 hyper threaded cores at a relatively low cost.
I expect the difference between the single threaded writer model and the concurrent writer model to be, in terms of ease of implementation and in terms of performance to be absolutely massive. However, when dealing with concurrent, long-running transactions (I shall come back to discussing what a transaction can be considered a long-running one) write transactions there is no substitute to the full model.

